12 Walkthrough 6: Exploring relationships using social network analysis with social media data
Abstract
This chapter explores the use of social network analysis, commonly referred to as SNA. While much of the data that data scientists in education analyze is about individuals, some data is about the relationships between individuals. Examples include friendship between youth or advice-seeking on the part of teachers. This is called network data. Network data can be difficult to analyze, in part due to multiple sources of data about individuals and their relationships to each other. This chapter uses data from the Bluesky #tidytuesday network, a weekly data visualization challenge, to demonstrate how to import data, prepare for social network analysis using the {tidygraph} R package, and visualize it using the {ggraph} R package.
12.2 Functions introduced
bskyr::bs_search_posts()bskyr::bs_auth()bskyr::set_bluesky_user()andbskyr::set_bluesky_pass()purrr::pluck()purrr::map_chr()tidyr::unnest()dplyr::rowwise()anddplyr::ungroup()stringr::str_extract()tidygraph::tbl_graph()tidygraph::activate()tidygraph::centrality_degree()tidygraph::centrality_betweenness()ggraph::ggraph()ggraph::geom_edge_link()ggraph::geom_node_point()ggraph::geom_node_text()
12.3 Vocabulary
- Application Programming Interface (API)
- edgelist
- edge
- influence model
- regex
- selection model
- social network analysis
- sociogram
- vertex
12.4 Chapter overview
In education, it’s common to focus on individuals –– students and teachers, especially. You can learn many things from studying individual students or teachers, but sometimes what is interesting lies between individuals. Social network analysis is useful for just this – understanding the relationships between individuals.
For instance, social network analysis is useful for asking questions about social influence (Frank, 1998), like How does the pattern of interactions among teachers in a professional network explain their continued involvement in the network? (Joshua M. Rosenberg & Willet, 2021) There are questions about social selection, like which parents are the most central in a parent teacher association (PTA) group?
In this chapter, you will focus on describing the interactions between #TidyTuesday participants using social network analysis (SNA) techniques as precursors to analyses about influence or selection. #TidyTuesday is a weekly social data project aimed at the R community. Every Monday, a new dataset is posted on social media, and participants create and share visualizations throughout the week, creating a vibrant online learning community.
While useful for asking questions about social relations, social network analysis can be hard. Cleaning and tidying the data, especially, can be tricky. Sometimes it’s more challenging than other data sources because data for social network analysis often includes variables about both individuals (information about students or teachers) and their relationships (whether a relationship exists, the strength of the relationship, or the type of the relationship).
This chapter is designed to take you from importing social media data through visualizing it. Though, as we describe next, you can also use self-report survey and other types of data, as well.
For those wishing to dive deeper into the aforementioned selection and influence models, we’ve included an appendix (Appendix) to introduce other social network-related ideas for further exploration; these focus on modeling social network processes. In particular, they include the processes for who chooses to interact with whom, their level of influence, or how the relationships impact behaviors.
You will need a Bluesky account to complete the code outlined in this chapter to access your own Bluesky data. You will use the Bluesky Application Programming Interface (API). If you do not have a Bluesky account, you can create one and keep it private or choose to delete it when you’re done with this walkthrough.
12.5 Background
Traditionally, social network analysis was carried out using self-report surveys. An example of this is Frank et al. (2004), where teachers were surveyed about who they turned to for advice about teaching. This data was then used to create a network of advice-seeking relationships among teachers.
More recently, researchers and analysts have used other data sources—especially data from digital tools, including social media (Joshua M. Rosenberg et al., 2020b).
In this chapter, you will access data using the {bskyr} package (Kenny, 2024), providing access to data from the Bluesky social media platform. In the first edition of this book, you used a different data source—Twitter (X) posts. Due to changes in the accessibility of that data, we have switched to a different social media platform, Bluesky.
There are a few things to know before getting started. First, as with most social media platforms, Bluesky places restrictions on accessing its Application Programming Interface (API). An API is a set of structured HTTP requests that return data in a predictable way. These restrictions limit the number of posts that can be accessed using the API. Bluesky’s rate limits are generally generous for typical educational research and #TidyTuesday analysis.
Occasionally, Bluesky will make changes to its API that affect how the {bskyr} package works. When this happens, you may need to wait for the package to be updated. It is a good idea to install the latest version of the package before beginning a new project by running install.packages("bskyr") or checking for updates.
In the past, if a teacher wanted advice about how to plan a unit or to design a lesson, they would turn to a trusted peer in their building or district (Spillane et al., 2012). Today they are as likely to turn to someone in a social media network. Social media interactions like the ones tagged with the #tidytuesday hashtag are increasingly common in education. Using data science tools to learn from these interactions is valuable for improving the student experience.
12.6 Packages
Fortunately, it is about as easy to access data from Bluesky as it was from Twitter, using R packages like {bskyr} and others. In addition to the {bskyr} package, you’ll load {tidygraph} (Pedersen, 2024) and {ggraph} (Pedersen, 2025) for network analysis and {randomNames} (Betebenner, 2024) for non-anonymized names. As always, if you have not installed these packages before (you won’t have used {bskyr}, {randomNames}, {tidygraph}, and {ggraph} at this stage of the book), do so using the install.packages() function. You can read more about installing packages in the “Packages” section of the “Foundational Skills” chapter.
Load the packages with the following calls to the library() function:
12.7 Data sources and import
There are two ways to walk through this chapter. The first option is for you to access data from Bluesky on your own. The other is to load the Bluesky data using the {dataedu} R package. The choice is yours! If you’d like to access the Bluesky data through the package, skip ahead to the “Loading already-accessed data” sub-section.
12.7.1 Accessing Bluesky data through the Application Programming Interface (API)
A common way to import data from websites, including social media platforms, is using an Application Programming Interface (API). In fact, if you ran the code above, you just accessed an API!
An API is like a special door for a house that has interesting things in it. The home builder doesn’t want everyone to walk right in. But they also don’t want to make it too hard because, after all, sharing is caring. The door is a special one, just for folks who know how to use them. Users need to know where to find it and once they’re there, they have to know the code to open it. Once they’re through, they have to know how to use the stuff inside.
An API for social media platforms like Bluesky works the same way. You can download datasets about social media posts using code and authentication credentials organized by the website.
There are advantages to using an API to import data at the start of your analysis. Every time you run the code in your analysis, you’ll use the API to contact the social media platform and download a fresh dataset. Now your analysis is updated with the most recent data every time you run it. By using an API to import new data every time you run your code, you repeat the analysis again and again on future datasets.
The Bluesky API, like most social media APIs, has rate limits on how many posts you can collect in a given time period. For typical educational research and #TidyTuesday analysis, these limits are usually sufficient. If you need to collect large amounts of historical data, you may need to spread your data collection over multiple sessions or days.
Let’s get started. The first step in using the {bskyr} package is gaining access to the Application Programming Interface. To do so, you’ll need to visit https://bsky.app/settings in a browser.
Then, go to “Privacy and Security”, and click “App passwords” and then “Add App Password”. You can use the randomly generated name.
Figure 12.1: Add app password
You do not need to check, “Allow access to your direct messages”.
A password will pop up (see the figure below) that you will copy and use next.
Figure 12.2: Example app password
You’re almost authenticated. You’ll run these two lines of code once. This saves your username and this passcode in a hidden file (called `.Renviron`) that you will use for all subsequent analyses.
set_bluesky_user("YOUR-USERNAME.bsky.social") # your username goes here -- including .bsky.social at the end!
set_bluesky_pass("your-app-password") # the passcode you just copied goes hereThe next line is one you’ll run every time you want to collect new Bluesky data in a fresh R session:
We’ll next collect some posts for the #tidytuesday hashtag on Bluesky.
Let’s start with one month – January 2025. We need to specify a few things:
the query
the date range
the maximum number of posts we want to collect
our authentication information
posts_jan <- bs_search_posts(query = "#tidytuesday",
since = '2025-01-01T00:00:00.000Z', until = '2025-01-31T23:59:59.000Z',
limit = 10000,
auth = auth)Let’s inspect the result:
This will show us the structure of the data returned by the Bluesky API, including columns for the post’s author, content (in the record field), and engagement metrics.
Let’s continue to collect four more months.
posts_feb <- bs_search_posts(query = "#tidytuesday",
since = '2025-02-01T00:00:00.000Z', until = '2025-02-28T23:59:59.000Z',
limit = 10000,
auth = auth)
posts_mar <- bs_search_posts(query = "#tidytuesday",
since = '2025-03-01T00:00:00.000Z', until = '2025-03-31T23:59:59.000Z',
limit = 10000,
auth = auth)
posts_apr <- bs_search_posts(query = "#tidytuesday",
since = '2025-04-01T00:00:00.000Z', until = '2025-04-30T23:59:59.000Z',
limit = 10000,
auth = auth)
posts_may <- bs_search_posts(query = "#tidytuesday",
since = '2025-05-01T00:00:00.000Z', until = '2025-05-31T23:59:59.000Z',
limit = 10000,
auth = auth)Now, we can combine these data frames and assign the results to a single object, posts, and then look at the results:
12.7.2 Loading already-accessed data
The code above shows you how to collect fresh data yourself for your own network analyses. But you can also load already-accessed data for this walkthrough if you’d prefer. The code below allows you to work through the analysis even if you don’t have a Bluesky account.
# Load the pre-collected data
# library(dataedu)
# posts <- dataedu::bluesky_posts
posts <- read_rds("posts.rds")You can easily change the search term to other hashtags or search terms. For example, to search for #rstats posts, we can replace #tidytuesday with #rstats.
rstats_posts <- bs_search_posts(query = "#rstats",
since = '2024-12-01T00:00:00.000Z',
until = '2024-12-31T23:59:59.000Z',
limit = 10000,
auth = auth)You may notice that the most recent posts containing the #tidytuesday hashtag are returned. What if you wanted to go further back in time? We’ll discuss this topic in the next section and in Appendix B.
12.8 Processing the data
This data is complex. Unlike the rectangular datasets (like spreadsheets) that you used in earlier chapters, social media data from APIs often comes in a nested, hierarchical structure. Think of it like a filing cabinet where each drawer contains folders, and each folder contains documents. You need to open each level to get to the information you want.
If you take a glimpse at posts, you’ll see that many of the columns are of the type “named list”:
## Rows: 575
## Columns: 13
## $ uri <chr> "at://did:plc:rdoz33zgr7u3duzutsru4ivv/app.bsky.feed.post…
## $ cid <chr> "bafyreibyclfepf25brkfuge6hzmxgbbnjzvb7asfulmsmyoz5jtqwzx…
## $ author <list> ["did:plc:rdoz33zgr7u3duzutsru4ivv", "tangandhara.bsky.s…
## $ record <list> ["app.bsky.feed.post", "2025-02-16T22:22:36.187Z", ["app…
## $ embed <list> ["app.bsky.embed.record#view", ["app.bsky.embed.record#v…
## $ reply_count <int> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0, 0, 0, 0, 0, 2, 0, …
## $ repost_count <int> 1, 2, 3, 2, 0, 1, 0, 1, 0, 0, 9, 0, 1, 2, 1, 3, 3, 1, 2, …
## $ like_count <int> 1, 11, 8, 8, 2, 6, 9, 1, 1, 0, 41, 6, 7, 1, 7, 17, 16, 6,…
## $ quote_count <int> 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, …
## $ indexed_at <chr> "2025-02-16T22:22:39.692Z", "2025-02-16T13:31:36.057Z", "…
## $ viewer <list> [FALSE, FALSE], [FALSE, FALSE], [FALSE, FALSE], [FALSE, …
## $ labels <list> [], [], [], [], [], [], [], [], [], [], [], [], [], [], …
## $ cursor <chr> "100", "100", "100", "100", "100", "100", "100", "100", "…What does this “named list” variable type mean? When you look at what looks like the author variable, you can see it’s more complex. That’s because the Bluesky API returns data in a format called JSON (JavaScript Object Notation), which isn’t always compatible with table data.
In a regular spreadsheet, each cell contains a single value (like “John” or “42”). But in a named list, a single cell can contain multiple related values. For the author list, this includes their username, display name, profile information, and more, all stored together in one complex cell. Take a look at one author’s information:
## $did
## [1] "did:plc:tbgv4ifhymub6viufudvzrgl"
##
## $handle
## [1] "dslc.io"
##
## $displayName
## [1] "Data Science Learning Community"
##
## $avatar
## [1] "https://cdn.bsky.app/img/avatar/plain/did:plc:tbgv4ifhymub6viufudvzrgl/bafkreicz6ehyop5uuj45sber5btyhvwkvcswdgoxqrkaodzw2rtxo5ar4e@jpeg"
##
## $viewer
## $viewer$muted
## [1] FALSE
##
## $viewer$blockedBy
## [1] FALSE
##
##
## $labels
## list()
##
## $createdAt
## [1] "2023-07-18T12:53:22.102Z"Note that there’s a similar situation for the field called “record”, which includes the time stamp for the post, its text (i.e., the contents of the post), languages specified, whether hashtags are included, mentions of other users, and whether the post is a reply.
We won’t run the following code, as the output is quite lengthy. But please try to run it. Just make sure you’ve loaded the posts data from earlier.
12.8.1 What is our network?
Before you dive into extracting data, let’s discuss what our network represents. Recall the discussion at the beginning of this chapter about the wide variety in types of networks. In this analysis, we’re creating a network where:
- Nodes (the dots) represent individual Bluesky users who participated in #tidytuesday
- Edges (the connections) represent interactions, like when one user mentions or replies to another user
This type of network can help us answer questions like: Who are the most influential members of the #tidytuesday community? Who connects different sub-groups within the community? Who is most active in engaging with others?
To build this network, you’ll need to extract the author’s unique identifier (their DID) to identify each person as a node in the network. But you can’t use it while it’s buried inside this nested list structure—that’s the challenge we’ll tackle next.
12.9 View data
Start with getting a sense of how much data you’re working with. Each row in the posts dataset represents one post that used the #tidytuesday hashtag:
## [1] 575That’s quite a bit of data to work with. Each of these posts may contain mentions of other users or be replies to other users. These will become the edges (connections) in our network.
12.10 Methods: processing data into network format
The network dataset needs a way to identify each participant’s role in the interaction. You’ll need to answer questions like: Did someone reach out to another for help? Was someone contacted by another for help? You can process the data by creating an “edgelist”.
An edgelist is a special type of table where each row represents an interaction between two parties. Think of it like a log of phone calls: each row records who called whom. Each row, which represents a single relationship, is referred to as an “edge”.
A note on terminology: You may encounter different terms for the same concepts in network analysis. Edges are sometimes referred to as “ties” or “relations,” and the people in a network (nodes) are sometimes called “vertices” or “actors.” These terms are generally interchangeable, though they may be used in different contexts or by different research communities.
An edgelist looks like the following example, where the sender (sometimes called the “nominator”) column identifies who is initiating the interaction and the receiver (sometimes called the “nominee”) column identifies who receives the interaction:
## # A tibble: 12 × 2
## sender receiver
## <chr> <chr>
## 1 Aitkens, Megan Reinwald, Brian
## 2 Loor, Kailib Martinez, Victor
## 3 Loor, Kailib Fairbank'S, Courtney
## 4 el-Beydoun, Mahfoodha Martinez, Victor
## 5 el-Beydoun, Mahfoodha Reinwald, Brian
## 6 el-Beydoun, Mahfoodha al-Salman, Lutfi
## 7 el-Iman, Suhail Fairbank'S, Courtney
## 8 el-Iman, Suhail Mondragon, Coyote-Cache
## 9 el-Iman, Suhail al-Salman, Lutfi
## 10 Cook, Naomi al-Ahmed, Suhaib
## 11 Lane, Jana Fairbank'S, Courtney
## 12 Lane, Jana al-Ahmed, SuhaibIn this edgelist, the sender column might identify someone who nominates another (the receiver) as someone they go to for help. The sender might also identify someone who interacts with the receiver in other ways, like “liking” or “mentioning” their posts. In the following steps, we will work to create an edgelist from the data from #tidytuesday on Bluesky.
12.10.1 Extracting nodes and edges
Above, you saw that the data is really complex and you saw what an edgelist looks like. To create your own edgelist from the data, you’ll need to extract two key pieces of information from posts:
- Nodes: The unique individuals (users) in our network
- Edges: The interactions between users (replies and mentions)
12.10.1.1 Creating a helper function
First, define a helper function to extract data from the nested list structures in the Bluesky data. Remember that the Bluesky data has information stored in complex nested lists (like boxes within boxes), and you’ll need a way to open these boxes and get the information inside. This function “reaches into” nested list structures and pulls out text values. If the value doesn’t exist, it returns NA instead of causing an error:
12.10.1.2 Extracting nodes
Now extract the nodes to see the unique users in the network. Each row in posts has an author column containing nested information. You’ll use map_chr() to apply the pluck_chr() function to each row. The ~ syntax creates a formula, and .x represents each individual author:
nodes <- posts %>%
mutate(
# Extract the DID (a unique identifier like a social security number for accounts)
did = map_chr(author, ~pluck_chr(.x, "did")),
# Extract the handle (like @username)
handle = map_chr(author, ~pluck_chr(.x, "handle")),
# Extract the display name (the name people see)
display_name = map_chr(author, ~pluck_chr(.x, "displayName"))
) %>%
# Keep only one row per unique DID (each person appears once)
distinct(did, .keep_all = TRUE) %>%
# Create our final node table with just the ID and a readable label
transmute(
did = did,
# coalesce() picks the first non-missing value: tries display_name first,
# then handle, then DID if both are missing
label = coalesce(display_name, handle, did)
)12.10.1.3 Extracting reply edges
Next, you’ll extract edges. These are the replies and mentions between users.
First, get the reply edges. When someone replies to another user’s post, they create a connection with the person they’re replying to:
reply_edges <- posts %>%
mutate(
# Who is doing the replying? (the "from" person)
from = map_chr(author, ~pluck_chr(.x, "did")),
# Who are they replying to? (the "to" person)
# Reply information is stored in record$reply$parent$uri
# This URI looks like: "at://did:plc:abc123/app.bsky.feed.post/xyz"
parent_uri = map_chr(record, ~pluck_chr(.x, "reply", "parent", "uri")),
# Extract just the DID from the URI using a pattern
# The pattern "did:[^/]+" means: find "did:" followed by any characters
# that aren't a forward slash. This extracts "did:plc:abc123" from the full URI
to = str_extract(parent_uri, "did:[^/]+")
) %>%
# Keep only rows where we found a valid recipient
filter(!is.na(to), to != "") %>%
# Keep just the from and to columns for our edgelist
select(from, to)12.10.1.4 Extracting mention edges
Second, get mention edges from facets in the post record. “Facets” are pieces of a post that have special meaning, like @mentions or #hashtags. When you @mention someone, that creates an interaction (edge) in the network:
mention_facet_edges <- posts %>%
mutate(
# Who wrote the post? (the "from" person)
from = map_chr(author, ~pluck_chr(.x, "did")),
# Extract the facets (special features) from each post's record
# Each post can have multiple facets (e.g., mentioning 3 different people)
facets = map(record, ~pluck(.x, "facets", .default = list()))
) %>%
# unnest() transforms the data: if a post has 3 facets, we create 3 rows
# (one row per facet). This lets us examine each mention separately.
# Think of it like expanding a compressed file
unnest(facets, keep_empty = FALSE) %>%
# Now we need to process each row individually to extract mention information
# rowwise() tells R: "treat each row separately, not as a whole column"
# This is like processing one student's test at a time instead of the whole class at once
rowwise() %>%
mutate(
# What type of feature is this? (mention, hashtag, link, etc.)
feature_type = pluck_chr(facets, "features", 1, "$type"),
# If it's a mention, who was mentioned? (the "to" person)
to = pluck_chr(facets, "features", 1, "did")
) %>%
# ungroup() tells R we're done processing row-by-row and can work with all rows again
ungroup() %>%
# Keep only the mentions (not hashtags or links), and only valid ones
filter(feature_type == "app.bsky.richtext.facet#mention", !is.na(to), to != "") %>%
# Keep just the from and to columns for our edgelist
select(from, to)12.10.1.5 Combining edges and cleaning nodes
Now you’ll combine both types of edges (replies and mentions) into one edgelist. The bind_rows() function stacks the two data frames on top of each other, and distinct() removes any duplicate interactions:
Finally, do some cleaning of the nodes data to make sure you don’t have any missing or blank IDs:
nodes <- nodes %>%
filter(!is.na(did), did != "") %>%
# Ensure each person appears only once
distinct(did, .keep_all = TRUE) %>%
# Make sure everyone has a label (if display_name and handle are missing, use DID)
mutate(label = coalesce(label, did))Have a look at what you’ve created. First, the nodes:
## Rows: 125
## Columns: 2
## $ did <chr> "did:plc:rdoz33zgr7u3duzutsru4ivv", "did:plc:s5sz3q5ffbgcdymwohl…
## $ label <chr> "Tan", "Georgios Karamanis", "Umair Durrani", "C.Robbs", "Víctor…And then the edges - both replies and mentions.
## Rows: 62
## Columns: 2
## $ from <chr> "did:plc:rdoz33zgr7u3duzutsru4ivv", "did:plc:ohi2xrnudescckz5bftp…
## $ to <chr> "did:plc:rdoz33zgr7u3duzutsru4ivv", "did:plc:ohi2xrnudescckz5bftp…Great! Now you have the network data structured properly. The next step is to prepare this data for visualization by converting it into a format that the {tidygraph} and {ggraph} packages can work with.
Network visualization packages need edges to reference nodes by their row numbers (like “person in row 5 mentioned person in row 12”) rather than by IDs. Think of it like seating charts: instead of saying “Emily mentioned Joshua,” you’d say “person in seat 5 mentioned person in seat 12.” This next section converts our edge data to use row numbers.
# Step 1: Create a lookup table that matches each DID to its row number
# This is like creating a class roster where each student has a seat number
node_index <- nodes %>%
mutate(.idx = row_number()) %>% # Assign row numbers: 1, 2, 3, ...
select(did, .idx) # Keep just the ID and row number
# Step 2: Convert edge endpoints from DIDs to row numbers
# We use left_join() to look up the row number for each "from" and "to" person
edges_idx <- mention_edges %>%
# First, make sure we only have valid, non-empty IDs
filter(!is.na(from), from != "", !is.na(to), to != "") %>%
# Look up the row number for the "from" person
left_join(node_index, by = join_by(from == did)) %>%
rename(.from_idx = .idx) %>%
# Look up the row number for the "to" person
left_join(node_index, by = join_by(to == did)) %>%
rename(.to_idx = .idx)
# Step 3: Check for edges that reference people not in our nodes list
# This can happen if someone mentioned a user who didn't post with #tidytuesday
bad_edges <- edges_idx %>% filter(is.na(.from_idx) | is.na(.to_idx))
if (nrow(bad_edges) > 0) {
message("Dropping ", nrow(bad_edges), " edges with unknown endpoints.\n",
"Examples:\n",
paste(utils::capture.output(print(head(bad_edges, 5))), collapse = "\n"))
}## Dropping 15 edges with unknown endpoints.
## Examples:
## # A tibble: 5 × 4
## from to .from_idx .to_idx
## <chr> <chr> <int> <int>
## 1 did:plc:aqr5h6q7clmeheft3sknegcl did:plc:qm2k6rvko6jfm2hd3j… 38 NA
## 2 did:plc:peeplnvlwcohp4jly3fpwj46 did:plc:tmg7lcns4qad5ijloi… 19 NA
## 3 did:plc:n5yjdgwqyts3aswafnbeolez did:plc:kqbyr4gqt6p2l57htl… 69 NA
## 4 did:plc:6hdxfihvnu4g6qarkvmy24ig did:plc:ahlayt6eklouieqqxl… 73 NA
## 5 did:plc:peeplnvlwcohp4jly3fpwj46 did:plc:cdlcedk4tzrnbd4blj… 19 NA# Step 4: Keep only valid edges and remove self-loops
# A "self-loop" is when someone mentions themselves (from_idx == to_idx)
# We filter these out because they're not meaningful interactions
edges_ok <- edges_idx %>%
filter(!is.na(.from_idx), !is.na(.to_idx)) %>% # Valid endpoints
filter(.from_idx != .to_idx) %>% # No self-loops
transmute(from = .from_idx, to = .to_idx) # Keep only the row numbers
# Step 5: Build the graph object
# tbl_graph() combines our nodes and edges into a single network object
# directed = TRUE means the direction matters (A->B is different from B->A)
g_mentions <- tbl_graph(nodes = nodes, edges = edges_ok, directed = TRUE)
g_mentions## # A tbl_graph: 125 nodes and 31 edges
## #
## # A directed simple graph with 99 components
## #
## # Node Data: 125 × 2 (active)
## did label
## <chr> <chr>
## 1 did:plc:rdoz33zgr7u3duzutsru4ivv Tan
## 2 did:plc:s5sz3q5ffbgcdymwohle4tmf Georgios Karamanis
## 3 did:plc:6hh6jl4cuhypppidh2yq3uc3 Umair Durrani
## 4 did:plc:o6kwi4owhlbhfftbkadi2uhu C.Robbs
## 5 did:plc:ezqzmmt3zxquxhqrvybw4bcr Víctor Gauto
## 6 did:plc:ihadlwi4yb2xvfvsnzhesb6s Steven Ponce
## 7 did:plc:zhqgbdi2odcfg2jhvrtyr7ek Andres Gonzalez
## 8 did:plc:jqfdjmap6g4psarvsxsfqi3n Yani Bellini Saibene
## 9 did:plc:435el47ddxdbziiobdihe5hh Yani Bellini Saibene
## 10 did:plc:ohi2xrnudescckz5bftpdk72 Ilya Kashnitsky
## # ℹ 115 more rows
## #
## # Edge Data: 31 × 2
## from to
## <int> <int>
## 1 11 1
## 2 11 57
## 3 60 54
## # ℹ 28 more rowsYou’ve now created a network graph object (g_mentions) that contains both the nodes (users) and edges (interactions). This graph is a directed network, meaning that the direction of the interaction — who mentioned or replied to whom — matters.
12.11 Analysis and results
Now that you have the network graph (g_mentions), you can analyze and visualize it. You’ll use the {tidygraph} and {ggraph} packages to calculate network metrics and create visualizations. Note that network visualizations are often referred to as “sociograms.” These represent the relationships between individuals in a network. We use “sociograms” and the term “network visualization” interchangeably in this chapter.
12.11.1 Descriptive statistics
Now you’ll calculate some important network measures that describe each person’s position and importance in the network. These are called “centrality” metrics:
In-degree: How many times was this person mentioned or replied to? This measures popularity or influence, like counting how many people call you for advice.
Out-degree: How many times did this person mention or reply to others? This measures how much someone reaches out to others.
Betweenness: How often does this person connect different groups? Think of this as being a “bridge” between different friend groups. High betweenness means you connect people who wouldn’t otherwise interact. You’ll normalize this measure (using
normalized = TRUE) to put it on a 0-1 scale for easier interpretation.
Calculate these metrics for each person in the network. Use activate(nodes) to tell {tidygraph} to work with the nodes table (remember, the graph has both nodes and edges, so you’ll need to specify which one):
g_metrics <- g_mentions %>%
activate(nodes) %>%
mutate(
in_deg = centrality_degree(mode = "in"),
out_deg = centrality_degree(mode = "out"),
btw = centrality_betweenness(directed = TRUE, normalized = TRUE)
)Now convert the network back to a regular table and add ranking columns. This helps identify the “top” people by each measure. Use desc() to rank from high to low (not low to high):
nodes_tbl <- g_metrics %>%
activate(nodes) %>%
as_tibble() %>%
mutate(
in_deg_rank = min_rank(desc(in_deg)),
out_deg_rank = min_rank(desc(out_deg)),
btw_rank = min_rank(desc(btw))
)Examine the top users by each centrality measure to identify the most influential members of the #tidytuesday community:
# View the top 10 most-mentioned users (highest in-degree)
nodes_tbl %>%
arrange(desc(in_deg)) %>%
select(label, in_deg, out_deg, btw) %>%
head(10)## # A tibble: 10 × 4
## label in_deg out_deg btw
## <chr> <dbl> <dbl> <dbl>
## 1 "Nicola Rennie" 6 8 0.00656
## 2 "Data Science Learning Community" 6 0 0
## 3 "Jon Harmon (he/him/his) " 3 3 0.00275
## 4 "Dan Oehm" 2 0 0
## 5 "Tan" 1 0 0
## 6 "Georgios Karamanis" 1 1 0.000656
## 7 "Steven Ponce" 1 0 0
## 8 "Ilya Kashnitsky" 1 2 0.00131
## 9 "Deepali Kank" 1 1 0
## 10 "Cédric Scherer" 1 0 0This table shows the most-mentioned users in our network. The in_deg column shows how many times each person was mentioned or replied to, while out_deg shows how many times they mentioned or replied to others. The btw (betweenness) score indicates how important they are for connecting parts of the network.
12.11.2 Plotting the network
Now create a visualization of the network. You’ll size nodes by their in-degree (how many mentions they received) and color them by betweenness centrality (how important they are for connecting parts of the network). To avoid clutter, only label the most-mentioned users:
# Prepare labels - we only want to show labels for the top 5% most-mentioned users
# quantile(x, 0.95) finds the value where 95% of data points are below it
# This helps us avoid overcrowding the plot with too many labels
label_threshold <- quantile(nodes_tbl$in_deg, 0.95, na.rm = TRUE)
# Create a label column: show name if person is in top 5%, otherwise NA (no label)
# ifelse() works like: ifelse(condition, value_if_true, value_if_false)
nodes_tbl <- nodes_tbl %>%
mutate(lbl = ifelse(in_deg >= label_threshold & in_deg > 0, label, NA))
# set.seed() ensures we get the same network layout every time we run this code
# Network layouts use random starting positions, so this makes our results reproducible
set.seed(42)
# Add the label column to our graph object too (we need it in both places)
g_metrics <- g_metrics %>%
activate(nodes) %>%
mutate(
lbl = ifelse(
in_deg >= quantile(in_deg, 0.95, na.rm = TRUE) & in_deg > 0,
label, NA_character_
)
)
# Create the network visualization
# ggraph works like ggplot2, but for networks
p_net <- ggraph(g_metrics, layout = "fr") + # "fr" = Fruchterman-Reingold layout
# This algorithm positions nodes so
# connected nodes are close together
# Draw the edges (connections between people) as gray lines
geom_edge_link(alpha = 0.8, linewidth = 0.2) +
# Draw the nodes (people) as points
# Size represents how many mentions they received (in_deg)
# Color represents their betweenness (how much they bridge groups)
geom_node_point(aes(size = in_deg, color = btw), alpha = 0.9) +
# Add text labels for the most-mentioned users
# vjust = -0.8 moves labels slightly above the points so they don't overlap
geom_node_text(aes(label = lbl), size = 3, vjust = -0.8, na.rm = TRUE) +
# Customize the size legend
scale_size_continuous(name = "In-degree (mentions)", range = c(2, 12)) +
# Customize the color legend (showing betweenness as percentages)
scale_color_continuous(name = "Betweenness", labels = label_percent(accuracy = 0.1)) +
# Adjust the color legend height for better readability
guides(color = guide_colorbar(barheight = unit(60, "pt"))) +
# Use a minimal theme (removes grid lines, axes, etc.)
theme_void() +
# Add a title
ggtitle("Mention network: size = in-degree, color = betweenness")
p_net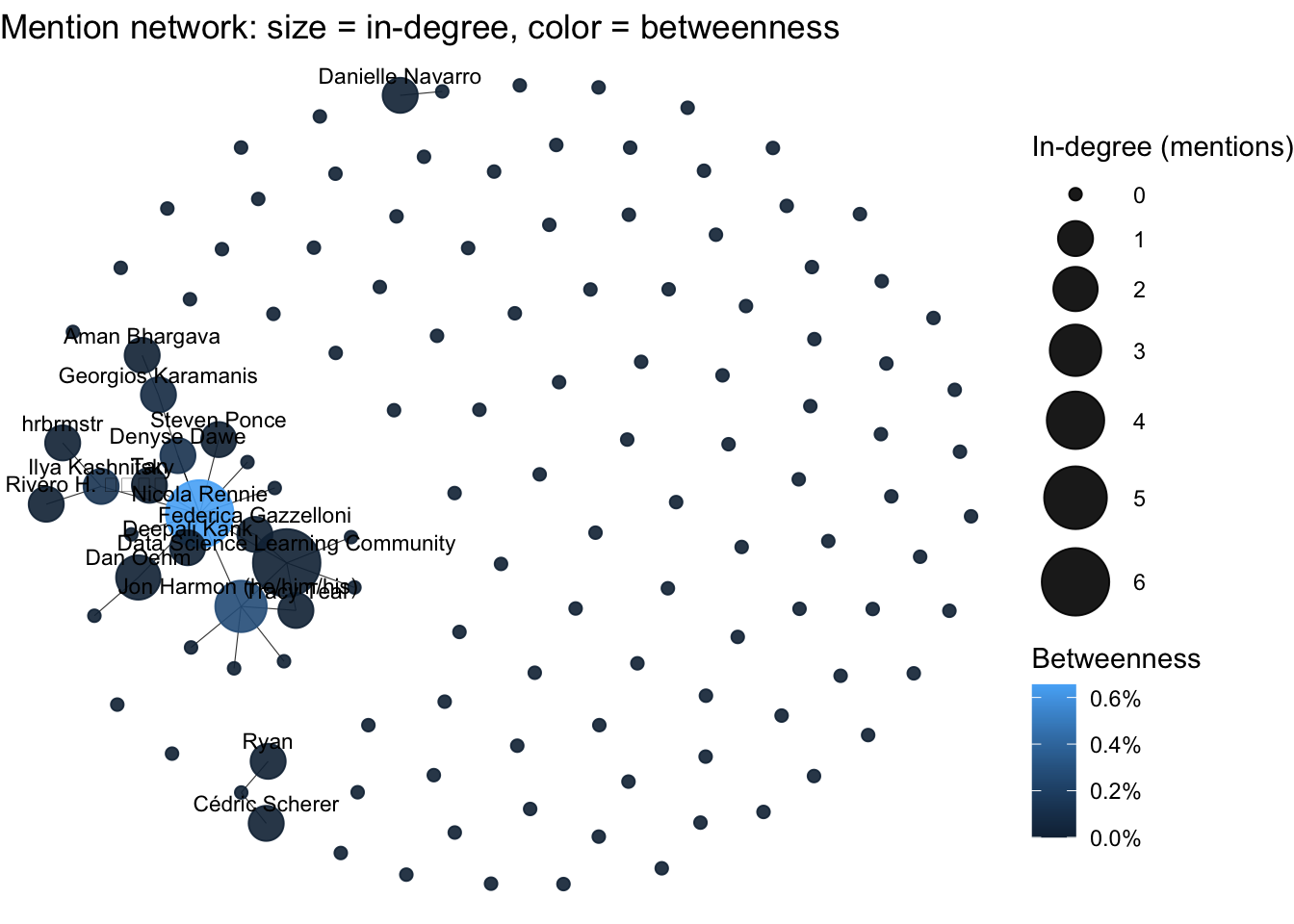
Figure 12.3: Network visualization
This visualization shows the structure of the #TidyTuesday network on Bluesky. Larger nodes represent users who receive more mentions, and the color indicates their betweenness centrality — how crucial they are in connecting parts of the network.
12.11.3 Refining the graph – filtering isolated nodes
Looking at the visualization above, you may notice isolated nodes—users who appear in the dataset but have no connections to others in the network. These isolated nodes can make the visualization cluttered and harder to interpret. Often, you’ll be most interested in the connected parts of the network where interactions actually occur.
Create a cleaner version by filtering out the isolated nodes. You can do this by keeping only nodes that have at least one connection, either mentioning someone or being mentioned:
# Filter the graph to remove isolated nodes
# centrality_degree(mode = "all") counts both incoming and outgoing connections
# Keeping only nodes with degree > 0 removes anyone with no connections
g_connected <- g_metrics %>%
activate(nodes) %>%
filter(centrality_degree(mode = "all") > 0)Now recreate the visualization with only the connected nodes:
set.seed(42)
p_connected <- ggraph(g_connected, layout = "fr") +
geom_edge_link(alpha = 0.8, linewidth = 0.2) +
geom_node_point(aes(size = in_deg, color = btw), alpha = 0.9) +
geom_node_text(aes(label = lbl), size = 3, vjust = -0.8, na.rm = TRUE) +
scale_size_continuous(name = "In-degree (mentions)", range = c(2, 12)) +
scale_color_continuous(name = "Betweenness", labels = label_percent(accuracy = 0.1)) +
guides(color = guide_colorbar(barheight = unit(60, "pt"))) +
theme_void() +
ggtitle("Connected #TidyTuesday network (isolated nodes removed)")
p_connected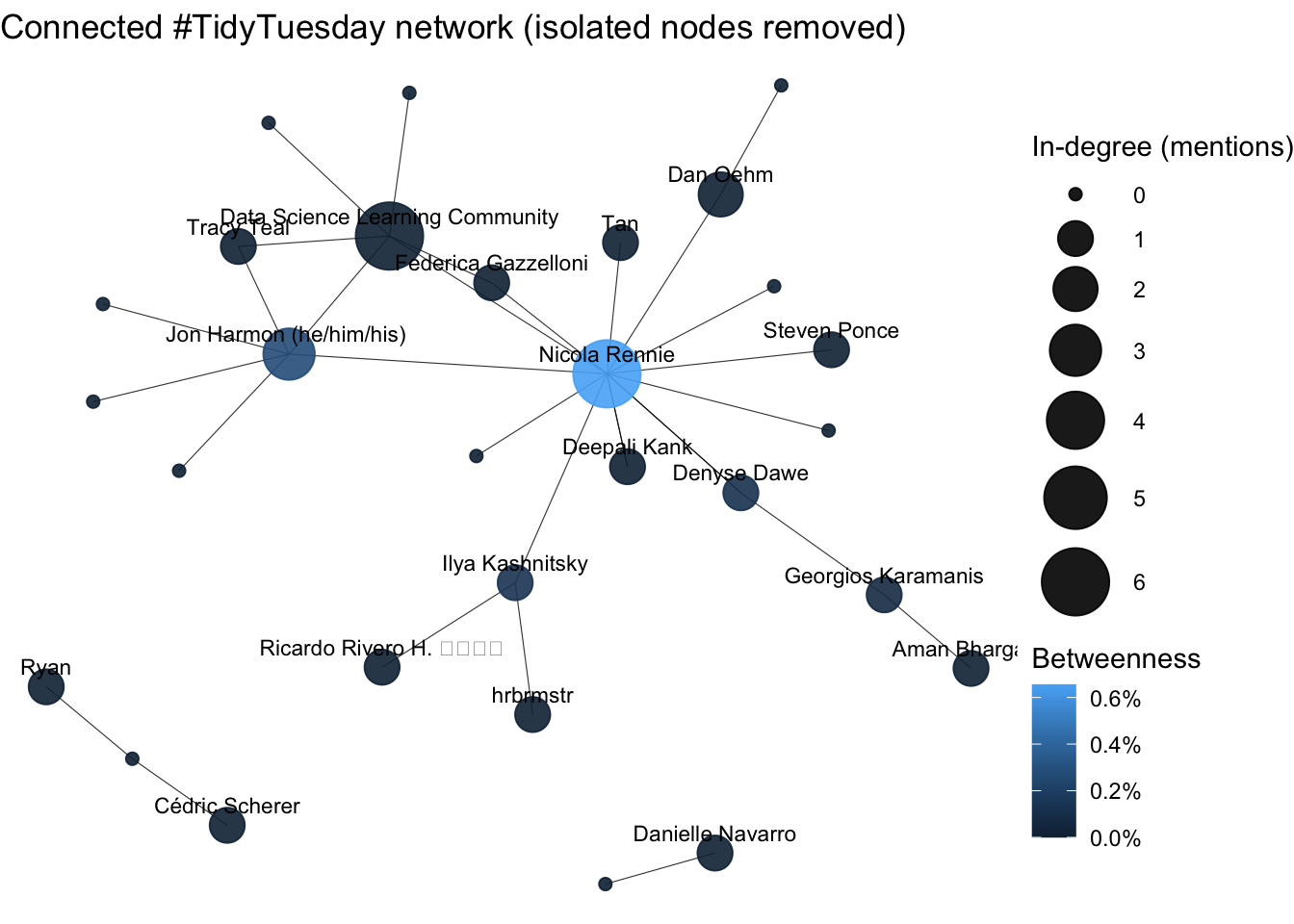
Figure 12.4: Network visualization with isolated nodes removed
This filtered visualization is cleaner and makes it easier to see the structure of interactions within the #TidyTuesday community. You can more clearly identify central figures, clusters of users who interact frequently, and bridges between different groups.
12.11.4 Interpreting the network through an educational lens
Social network analysis reveals patterns about learning communities and knowledge sharing that are relevant to educational practice. Looking at our #TidyTuesday network, you can identify several key roles:
Influential members appear as larger nodes and have high in-degree. In educational settings, these are the teacher leaders or coaches that others turn to for guidance. Their prominence suggests they’re creating valuable content or providing support that resonates with the community.
Active engagers have high out-degree. They frequently reach out to others. In schools, these connectors maintain community vitality by initiating conversations and fostering collaboration, even if they’re not the most “popular” members.
Bridge-builders have high betweenness. These appear as light blue nodes, connecting otherwise separate clusters. In educational contexts, these might be teachers who work across departments or administrators who link different communities. They’re crucial for information flow and preventing isolated silos.
The network structure itself offers insights: tight clusters might represent communities of practice, while peripheral members reflect newcomers learning through observation before deeper participation. Understanding these patterns can help educators foster inclusive participation, leverage influential voices strategically, cultivate bridge-builders across groups, and monitor overall network health, ensuring the community has stable leadership without over-dependence on a few individuals.
There is much more you can do with {ggraph} (and {tidygraph}); check out the {ggraph} tutorial here: https://ggraph.data-imaginist.com/ to explore additional layout algorithms, styling options, and advanced network visualizations.
12.12 Conclusion
In this chapter, you used social media data from the #tidytuesday hashtag on Bluesky to prepare and visualize social network data. Sociograms are useful for revealing who interacts with whom—and in some cases, to suggest why. In data science, you’ll find that individuals (such as teachers or students) in a network often learn by visualizing these relationships. It’s compelling to think about why networks are the way they are and what changes could be made to foster more connections between individuals who have few opportunities to interact. In this way, social network analysis can be a technique to communicate with other educational stakeholders in a compelling way.
Social network analysis is a broad and growing domain, and this chapter was intended to present some of its foundation. Fortunately for R users, many recent developments are implemented first in R (e.g., (R-amen?)). If you are interested in some additional steps that you can take to model and analyze network data, consider the appendix on models for selection and influence processes, Appendix B.